
봄디의 개발일지
[JAVA] Set 총 정리 (HashSet, LinkedHashSet, TreeSet) 본문
1️⃣ Set 이란?
Set 은 집합이라는 의미로 유일한 요소의 컬렉션을 말합니다.
Set 의 특징으로는 유일성, 순서 미보장, 빠른 검색 등이 있습니다.
유일성 : Set 에는 중복된 요소가 존재하지 않습니다. Set 에 요소를 추가할 때 이미 존재하는 요소라면 무시됩니다.
순서 미보장 : 대부분의 Set 구현에서는 순서를 보장하지 않습니다. 따라서 요소를 출력할 때 입력 순서와 다를 수 있습니다. (LinkedHashSet 제외)
빠른 검색 : Set 은 요소의 유무를 빠르게 확인할 수 있도록 최적화 되어 있습니다.
한마디로 Set 을 정의하자면 중복을 허용하지 않고, 순서를 보장하지 않는 자료 구조 입니다.
자바의 Set 인터페이스는 java.util 패키지에 속하는 인터페이스 중 하나입니다.
Set 인터페이스는 HashSet, LinkedHashSet, TreeSet 등의 여러 구현 클래스를 가지고 있습니다.

✅ HashSet
HashSet 을 이해하기에 앞서 Hash 개념에 대해 살펴보겠습니다.

우선 Hash 함수란 ?
Hash 함수는 임의의 길이의 데이터를 입력으로 받아, 고정된 길이의 해시값을 출력하는 함수입니다.
Hash 함수를 통해 해시 코드가 나오게 되고, 해시 코드는 데이터를 대표하는 값을 뜻합니다.
위의 예시에서는 A 가 해시 함수를 통해 나온 해시 코드는 65 이며, B 의 해시코드는 66, AB 의 해시코드는 131이 됩니다.
해시 인덱스(Hash Index) 란 ?
해시 인덱스를 통해 데이터의 저장 위치를 결정하는데, 주로 해시 코드를 사용해서 만들게 됩니다.
보통은 해시 코드의 결과에 배열의 크기를 나누어 해시 인덱스를 구합니다.
위의 예시에서는 A 의 해시코드는 65이며, 해시 인덱스는 5가 됩니다. 따라서 5번 인덱스 위치에 "A" 값이 저장되게 됩니다.
B 의 해시코드는 66이며, 해시 인덱스는 6이 됩니다. 따라서 6번 인덱스 위치에 "B" 값이 저장됩니다.
HashSet 이란 ?
HashSet 이란 해시 자료구조를 사용해서 요소를 저장하는 Set 인터페이스의 구현 클래스입니다.
HashSet 의 주요 연산인 추가, 삭제, 검색 은 평균적으로 O(1) 의 시간 복잡도를 가집니다.
HashSet 은 Set 과 동일하게 중복된 값을 허용하지 않으며, 순서가 보장되지 않는 특징을 가지고 있습니다.
HashSet 사용법
// HashSet<String> hashSet0 = new HashSet<>(10); //크기 지정 가능
HashSet<String> hashSet = new HashSet<>();
hashSet.add("spring");
hashSet.add("summer");
hashSet.add("fall");
hashSet.add("winter");
hashSet.add("spring"); //중복된 값 (저장되지 않음)
System.out.println(hashSet); //순서가 보장되지 않음 [spring, fall, winter, summer]
HashSet 에 "spring" 이라는 값을 중복해서 넣을 경우 들어가지 않습니다.
또한 HashSet 을 선언할 때 크기 지정도 가능하며, 제네릭을 선언하여 사용합니다.
hashSet 으로 출력결과를 확인해보면 저의 경우는 [spring, fall, winter, summer] 이렇게 결과값이 나왔듯이
입력된 순서와 관계없이 순서가 보장되지 않는다는 것을 확인해볼 수 있습니다.
Set 인터페이스의 주요 메서드는 아래에서 정리하도록 하겠습니다.
✅ LinkedHashSet
LinkedHashSet 은 HashSet 에 연결 링크만 추가한 구현 클래스입니다.
HashSet 에 LinkedList 를 합친 것으로 이해하시면 됩니다.

LinkedHashSet 은 연결 링크를 가지고 있고, 이 연결 링크들은 데이터를 입력한 순서대로 연결해줍니다.
따라서 Set 의 구현 클래스 중 유일하게 입력된 순서를 보장된다고 말할 수 있습니다.
HashSet 과 마찬가지로 중복된 값은 허용하지 않습니다.
마찬가지로 Hash 를 사용하기 때문에 주요 연산인 추가, 삭제, 검색 은 평균적으로 O(1) 의 시간 복잡도를 가집니다.
그러나, 연결 링크가 추가되었기 때문에 HashSet 보다는 좀 더 느립니다.
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("spring");
linkedHashSet.add("summer");
linkedHashSet.add("fall");
linkedHashSet.add("winter");
linkedHashSet.add("spring"); //중복된 값 (저장되지 않음)
System.out.println(linkedHashSet); // [spring, summer, fall, winter]
LinkedHashSet 은 HashSet 과는 달리 입력된 순서를 보장해주기 때문에
위의 linkedHashSet 을 출력해보면 [spring, summer, fall, winter] 입력한 순서대로 결과값이 나오는 것을 확인할 수 있습니다.
✅ TreeSet
TreeSet 을 이해하기에 앞서 Tree 구조에 대해 먼저 살펴보겠습니다.
Tree 구조란 ?
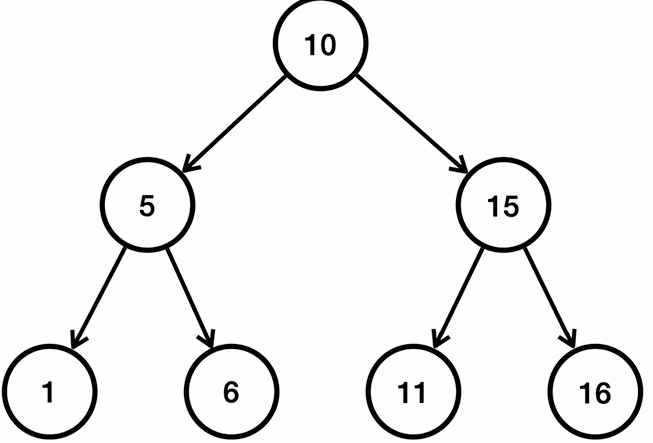
Tree 구조는 부모 노드와 자식 노드로 구성되어있으며, 가장 높은 조상을 root (루트) 라고 부릅니다.
TreeSet 에서는 이진 탐색 트리를 개선한 레드-블랙 트리를 사용하는데
기본 개념을 비슷하므로 이진 탐색이 무엇인지 간략하게 알아보겠습니다.
이진 탐색트리란 ?
우선 자식을 2개까지 가질 수 있는 트리를 이진 트리라고 하며,
노드의 왼쪽 자식은 더 작은 값을 가지고, 오른쪽 자식은 더 큰 값을 가지는 것을 이진 탐색 트리라고 부릅니다.
위의 그림에서는 6 을 예시로 설명을 하자면, 6은 10보다 작은 값이므로 10의 왼쪽 자식에 들어가게되고
5보다는 큰 값이므로 5의 오른쪽 자리에 위치하게 됩니다.
위의 그림에서 11이라는 값이 있는지 찾는다고 가정을 해보겠습니다.
루트인 10보다 찾으려는 값인 11이 더 큰 값이므로 10의 오른쪽에서 11이 있는지 찾게 됩니다.
그 다음 15보다는 11이 작은 값이므로 15의 왼쪽 자식에서 11이 있는지 찾게 됩니다.
15의 왼쪽으로 갔더니 11 이 있으므로 해당하는 값을 찾았습니다.
이렇게 이진 탐색 트리의 특성으로 한 번에 절반의 값은 비교하지 않고 절반의 데이터 중에서만 찾을 수 있습니다.
따라서 이진 탐색 트리는 O (log n) 의 성능을 가집니다.
이진 탐색 트리는 순회할 때 중위 순회 방법을 사용합니다.
중위 순회란? 왼쪽 서브트리를 먼저 방문하고, 본인의 노드를 방문하고, 오른쪽 서브트리를 방문하는 것을 말합니다.
왼쪽 자식에는 본인의 노드보다 작은 값이, 오른쪽 자식에는 본인의 노드보다 큰 값이 들어있으므로
순회를 하면 오름차순으로 방문하게 됩니다.
이제 본론으로 들어가서 TreeSet 이란 ?
TreeSet 역시 중복을 허용하지 않습니다.
HashSet 과 LinkedHashSet 과의 차이점이 있다면 데이터 값을 기준으로 정렬한다는 특징이 있습니다.
TreeSet 의 이진 탐색 트리가 순회를 할 때 중위 순회로 돌기 때문에 TreeSet 의 결과 역시 데이터 값을 기준으로 정렬이 됩니다.
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(1);
treeSet.add(5);
treeSet.add(3);
treeSet.add(2);
treeSet.add(4);
treeSet.add(1); //중복된 값 (저장되지 않음)
System.out.println(treeSet); //[1, 2, 3, 4, 5]
위의 코드에서 보면 TreeSet 은 중복으로 들어온 값은 저장하지 않고,
treeSet 으로 출력을 했을 때 오름차순으로 정렬된 것을 확인할 수 있습니다.
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(1);
treeSet.add(5);
treeSet.add(3);
treeSet.add(2);
treeSet.add(4);
treeSet.add(1); //중복된 값 (저장되지 않음)
Iterator<Integer> iterator = treeSet.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " "); // 1 2 3 4 5
}
참고로 Iterator 를 통해서 컬렉션을 반복해서 출력할 수 있습니다.
✅ HashSet, LinkedHashSet, TreeSet 정리 !!
- HashSet : 입력한 순서를 보장하지 않는다. (중복된 값을 허용하지 않고, 순서가 상관없을 때 사용)
- LinkedHashSet : 입력한 순서를 정확히 보장한다. (중복된 값은 허용하지 않고, 입력으로 들어온 순서가 중요할 때 사용)
- TreeSet : 데이터 값을 기준으로 정렬한다. (중복된 값은 허용하지 않고, 오름차순 혹은 데이터 값 기준으로 정렬이 필요할 때 사용)
🔍 참고글
인프런 [김영한의 실전 자바 - 중급 2편] 섹션 9. 컬렉션 프레임워크 - Set 강의를 참고하여 작성했습니다.
'자바' 카테고리의 다른 글
| [JAVA] valueOf() , intValue, parseInt() 정리 (0) | 2024.11.10 |
|---|---|
| [JAVA] Set 의 주요 메서드 정리 (6) | 2024.10.27 |
| [JAVA] ArrayList 자주 사용하는 메소드 (List/LinkedList) (0) | 2024.10.06 |
| [JAVA] 컬렉션 - List 정리 (ArrayList, LinkedList) (3) | 2024.10.06 |
| [JAVA] 자바 메모리 구조 (2) | 2024.09.15 |



